
Posted on 06/18/2013 10:14:55 AM PDT by Ernest_at_the_Beach

Intel on Monday announced the expansion of the Intel Xeon Phi coprocessors portfolio and revealed details of the second generation of Intel Xeon Phi products code named “Knights Landing”. The new products and technologies will continue to radically increase the energy efficiency and performance of supercomputers worldwide.
Intel revealed details of its second generation Intel Xeon Phi products aimed to further increase their supercomputing capabilities. Code-named “Knights Landing”, the next generation of Intel MIC architecture-based products will be available as a coprocessor or a host processor (CPU) and manufactured using Intel's 14nm process technology featuring second generation tri-gate transistors.
As a PCIe card-based coprocessor, "Knights Landing" will handle offload workloads from the system's Intel Xeon processors and provide an upgrade path for users of current generation of coprocessors, much like it does today. However, as a host processor directly installed in the motherboard socket, it will function as a CPU and enable the next leap in compute density and performance per watt, handling all the duties of the primary processor and the specialized coprocessor at the same time. When used as a CPU, "Knights Landing" will also remove programming complexities of data transfer over PCIe, common in accelerators today.
To further boost the performance for HPC workloads, Intel will significantly increase the memory bandwidth for all "Knights Landing" products by introducing integrated on-package memory. This will allow customers to take full advantage of available compute capacity without encountering memory bandwidth bottlenecks experienced today.
"Intel is helping to blaze a path toward new innovation, discovery and competitiveness with its supercomputing vision and products. There is an insatiable demand for more computing power while also achieving new levels of power efficiency. With the current and future generations of Intel Xeon Phi coprocessors, Intel Xeon processors, Intel TrueScale fabrics and software, Intel is uniquely equipped to deliver a comprehensive solution for our customers without compromise," said Raj Hazra, vice president and general manager of technical computing group at Intel.
Intel also announced the expansion of its current generation Intel Xeon Phi coprocessors with the addition of five new products that feature various performance options, memory capacity, power efficiency and form factors that are available today. The Intel Xeon Phi coprocessor 7100 family is designed and optimized to provide the best performance and offer the highest level of features, including 61 cores clocked at 1.23GHz, 16GB of memory capacity support (double the amount previously available in accelerators or coprocessors) and over 1.2TFlops of double precision performance. The Intel Xeon Phi coprocessor 3100 family is designed for high performance per dollar value. The family features 57 cores clocked at 1.1GHz and 1TFlops of double precision performance.
Lastly, Intel added another product to the Intel Xeon Phi coprocessor 5100 family announced last year. Named the Intel Xeon Phi coprocessor 5120D, it is optimized for high-density environments with the ability to allow sockets to attach directly to a mini-board for use in blade form factors.
The worldwide high performance computing (HPC) server segment is expected to grow its annual revenue by 36 percent1 from $11 billion to $15 billion over the next four years. The dramatic increase and growth of supercomputers continues to be driven by the need to quickly compute, simulate and make more informed decisions across a range of industries. Supercomputers are used to increase the accuracy of weather predictions, help to explore more efficient energy resources, develop cures for diseases, sequence the human genome and analyze big data.
fyi
They laughed at me for keeping that steel case with the Turbo button, but I’ll show them, oh, yes, I will... BTT
Everything old is new again. Glad to see Intel looking back to the Amiga 1200/Math coprocessor board ;)
Seriously though, whatever gets the job done faster. Makes a lot more sense to me than having to get new MBs with every chip advance. Just plug in a few more cards and haul bits.
Too much “Game of Thrones” for the geeks at Intel.
Intel Advances Technical Computing With New Xeon Phi Products

Dang, what goes around comes around. That thing looks like a Pentium II Slot One processor. And co-processors? Dang, back to the ‘287 and Weitek chips.
Intel previews future 'Knights Landing' Xeon Phi x86 coprocessor with integrated memory
ISC 2013 X86 processor and now coprocessor maker Intel is determined make possible an exaflops of aggregate computing capacity within a 20-megawatt envelope.
"We believe that we have the capability and the responsibility to drive innovation faster and faster," says Rajeeb Hazra, general manager of the Technical Computing Group, which is part of Intel's Data Center and Connected Systems Group.
That means a slew of different things, of course, but the ultimate goal in delivering that exascale system is cramming a petaflops of double-precision floating point performance into a half rack.
One step on that path is to get a much-improved version of the Xeon Phi coprocessor to market; one that packs more of a wallop, uses less juice, and that can plug into normal processor sockets as well as being used in PCI-Express coprocessors.
El Reg discussed this possibility of plunking the Xeon Phi coprocessor into a Xeon socket with CTO Justin Rattner several years back. At the International Super Computing conference in Leipzig, Germany, Hazra confirmed that was indeed the plan with the future "Knights Landing" kicker to the current "Knights Corner" Xeon Phi coprocessor that came out last November and that is being used in a wider range of form factors with more variations in performance starting today as well.
Intel is not saying precisely what processor socket the future Knights Landing chip will slip into, but the most obvious one is the socket shared by the Xeon E5 of the time. All that Hazra would confirm was that the idea is to deploy 14-nanometer processes to cram more transistors onto the Knights Landing chip and to get around some of the bottlenecks with the PCI-Express 3.0 bus that current coprocessors of any kind are adversely affected by.
It would be interesting and useful if the Xeon CPU and the Xeon Phi coprocessor functioning in standalone CPU mode could share the same memory. With DDR3 main memory offering far less bandwidth and higher latency than GDDR5 graphics memory, it is tricky for Intel to unify the memory architecture of the two processors.
At 3.2 giga transfers per second, DDR4 memory is expected to operate at twice the speed as DDR3, and because it runs at 1.2 volts, it will also use less power. This is about the same performance level as GDDR5 memory, by the way. The trouble is, future Xeon Phi coprocessors, with presumably many more cores thanks to the shift from 22 nanometer to 14 nanometer processes, might need twice as much memory bandwidth to feed them. There are a lot of ifs and unknowns, and Hazra is not about to tip Chipzilla's hand. He would not discuss if memory for the future Xeon Phi would link in over the QuickPath Interconnect or by some other means, but he did say that Intel would be stacking the memory onto the processor package and that Knights Landing would have "leadership compute and memory bandwidth".
Hazra did not say when Intel expected to deliver the Knights Landing variant of the Xeon Phi coprocessors and standalone multicore processors, but El Reg can do some guessing. The first 14-nanometer client parts, based on the "Broadwell" kicker to the just-announced "Haswell" Core and Xeon E3 chips is e due in 2014.
While it is possible that Knights Landing could be etched on 14 nanometer tech shortly thereafter, it seems likely that the company will try to time it to a Xeon E5 launch that uses the same processor socket. It is pretty safe to bet that Knights Landing will come out in the next 18 to 24 months, and that might mean that Intel could do a die shrink (a tock in the Intel parlance) on the current Knights Corner Xeon Phi to goose its clockspeed between now and then.
It would be very interesting indeed if Knights Landing also had its own integrated interconnect circuits, such as an Ethernet or InfiniBand adapter or two; it seems unlikely that Intel would park an "Aries" router chip on the Knights Landing die, or any other kind of full-blown or distributed switch, either. Intel has made no specific promises of an interconnect for any Xeon Phi. (Aries is the very scalable Dragonfly topology interconnect that Intel paid $140m last year to acquire from supercomputer maker Cray; it is used currently in the Cray XC30 super.)
What Intel has said, and what it reiterated again today at ISC, is that it understands that eventually, because of the increasing bandwidth needs of many-core processors (be they Xeon or Xeon Phi), the bottlenecks of the PCI-Express bus must be overcome.
**********************************
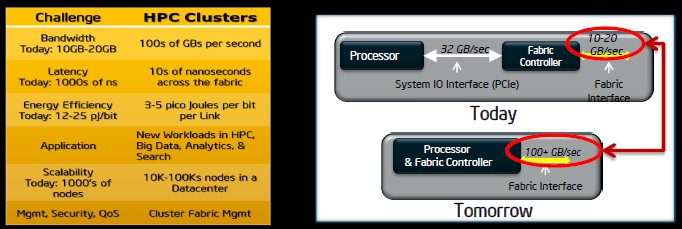
Over time, the interconnect fabric will be merged with Intel's CPUs (click to enlarge)
The current way of building systems has too much hopping around from component to component/ This was the case in systems from years ago, which had computing elements, now embedded on a CPU, spread out across a motherboard. That was the only way to manufacture a system at the time, by putting the processor, memory controllers, memory chips, various caches, and I/O processors all on a printed circuit. Intel has done the best job in the server processor space when it comes to integrating features, with PCI-Express 3.0 controllers on the current Xeon E5 dies and Ethernet controllers integrated on the current "Haswell" Xeon E3 processors (on the chipset southbridge) and on the impending "Avoton" Atom S1200-v2 processors (on the die perhaps) later this year.
Oracle-Sun has also done a good job integrating networking onto its Sparc T series chips, but IBM has not gotten around to supporting PCI-Express 3.0 peripherals or integrating Ethernet protocols onto its Power chips. (The Power chips do have an InfiniBand-derived port on the Power processors, called GX++, that is used to link remote I/O drawers directly to the chips.)
Intel agrees that chip makers (the few who are left) must get high-speed, fat-bandwidth interconnect fabrics onto the processors if it hopes to help others build their exascale-class machines. In current systems, the system I/O interface links the processor to the fabric controller, and that controller talks out to an interface that runs at between 10GB/sec and 20GB/sec. But this will not do at all. Future HPC clusters will need to be able to handle hundreds of gigabytes per second of bandwidth, with latencies on the order of tens of nanoseconds across the fabric rather than the thousands of nanoseconds of modern fabrics.
Communications is perhaps the most energy hungry part of the modern network, and the goal, says Hazra, is to be able to move a bit over a communications link at the cost of 3 to 5 picojoules (pJ) per bit. The fabrics that companies are building today can span thousands of server nodes, but in the future that Intel sees coming, we will only need to link 10,000 to 100,000 nodes, and Chipzilla envisions that the fabric controller etched on the same dies as the processor cores will link out to a fabric interface with 100GB/sec or higher bandwidth.
Hazra expects the on-chip fabric interface to run at 100GB/sec or more. When it is all done, you have fewer chips in the system, fewer hops, and fewer on-board, high-speed I/O signals. ®
Disclaimer: Opinions posted on Free Republic are those of the individual posters and do not necessarily represent the opinion of Free Republic or its management. All materials posted herein are protected by copyright law and the exemption for fair use of copyrighted works.