 No, it’s not Spiderman’s latest web slinging tool but something that’s more real world. Like the World Wide Web.
No, it’s not Spiderman’s latest web slinging tool but something that’s more real world. Like the World Wide Web.Posted on 03/23/2010 3:15:34 AM PDT by Daffynition
No, it’s not Spiderman’s latest web slinging tool but something that’s more real world. Like the World Wide Web.
The Invisible Web refers to the part of the WWW that’s not indexed by the search engines. Most of us think that that search powerhouses like Google and Bing are like the Great Oracle…they see everything. Unfortunately, they can’t because they aren’t divine at all; they are just web spiders who index pages by following one hyperlink after the other.
But there are some places where a spider cannot enter. Take library databases which need a password for access. Or even pages that belong to private networks of organizations. Dynamically generated web pages in response to a query are often left un-indexed by search engine spiders.
Search engine technology has progressed by leaps and bounds. Today, we have real time search and the capability to index Flash based and PDF content. Even then, there remain large swathes of the web which a general search engine cannot penetrate. The term, Deep Net, Deep Web or Invisible Web lingers on.
To get a more precise idea of the nature of this ‘Dark Continent’ involving the invisible and web search engines, read what Wikipedia has to say about the Deep Web. The figures are attention grabbers – the size of the open web is 167 terabytes. The Invisible Web is estimated at 91,000 terabytes. Check this out – the Library of Congress, in 1997, was figured to have close to 3,000 terabytes!
How do we get to this mother load of information?
That’s what this post is all about. Let’s get to know a few resources which will be our deep diving vessel for the Invisible Web. Some of these are invisible web search engines with specifically indexed information.

Infomine has been built by a pool of libraries in the United States. Some of them are University of California, Wake Forest University, California State University, and the University of Detroit. Infomine ‘mines’ information from databases, electronic journals, electronic books, bulletin boards, mailing lists, online library card catalogs, articles, directories of researchers, and many other resources.
You can search by subject category and further tweak your search using the search options. Infomine is not only a standalone search engine for the Deep Web but also a staging point for a lot of other reference information. Check out its Other Search Tools and General Reference links at the bottom.

This is considered to be the oldest catalog on the web and was started by started by Tim Berners-Lee, the creator of the web. So, isn’t it strange that it finds a place in the list of Invisible Web resources? Maybe, but the WWW Virtual Library lists quite a lot of relevant resources on quite a lot of subjects. You can go vertically into the categories or use the search bar. The screenshot shows the alphabetical arrangement of subjects covered at the site.

Intute is UK centric, but it has some of the most esteemed universities of the region providing the resources for study and research. You can browse by subject or do a keyword search for academic topics like agriculture to veterinary medicine. The online service has subject specialists who review and index other websites that cater to the topics for study and research.
Intute also provides free of cost over 60 free online tutorials to learn effective internet research skills. Tutorials are step by step guides and are arranged around specific subjects.

Complete Planet calls itself the ‘front door to the Deep Web’. This free and well designed directory resource makes it easy to access the mass of dynamic databases that are cloaked from a general purpose search. The databases indexed by Complete Planet number around 70,000 and range from Agriculture to Weather. Also thrown in are databases like Food & Drink and Military.
For a really effective Deep Web search, try out the Advanced Search options where among other things, you can set a date range.

Infoplease is an information portal with a host of features. Using the site, you can tap into a good number of encyclopedias, almanacs, an atlas, and biographies. Infoplease also has a few nice offshoots like Factmonster.com for kids and Biosearch, a search engine just for biographies.

DeepPeep aims to enter the Invisible Web through forms that query databases and web services for information. Typed queries open up dynamic but short lived results which cannot be indexed by normal search engines. By indexing databases, DeepPeep hopes to track 45,000 forms across 7 domains.
The domains covered by DeepPeep (Beta) are Auto, Airfare, Biology, Book, Hotel, Job, and Rental. Being a beta service, there are occasional glitches as some results don’t load in the browser.

IncyWincy is an Invisible Web search engine and it behaves as a meta-search engine by tapping into other search engines and filtering the results. It searches the web, directory, forms, and images. With a free registration, you can track search results with alerts.

DeepWebTech gives you five search engines (and browser plugins) for specific topics. The search engines cover science, medicine, and business. Using these topic specific search engines, you can query the underlying databases in the Deep Web.

Scirus has a pure scientific focus. It is a far reaching research engine that can scour journals, scientists’ homepages, courseware, pre-print server material, patents and institutional intranets.

TechXtra concentrates on engineering, mathematics and computing. It gives you industry news, job announcements, technical reports, technical data, full text eprints, teaching and learning resources along with articles and relevant website information.
Just like general web search, searching the Invisible Web is also about looking for the needle in the haystack. Only here, the haystack is much bigger. The Invisible Web is definitely not for the casual searcher. It is a deep but not dark because if you know what you are searching for, enlightenment is a few keywords away.
Do you venture into the Invisible Web? Which is your preferred search tool?
Image credit: MarcelGermain
bfl
THX
Thank you very much for the post. BTTT.
bookmark
Worth a ping to the list? More sources to explore...
ping
B4L8r
To put things in perspective, I have about 6 terabytes of storage in my house.
Bookmarking,
Thanks, this is very cool.

Thank you for posting this, Daffynition. I forwarded it to my daughters. They might be able to make use of it in what they for work. They’ve been able to use info supplied by FReepers on a couple of occasions.
Thanks, very helpful.
PING
There are still gopher, archie, and veronica servers out there. (Old timers will know what I mean)
Oh, really???
The source that (mistaken) claim (http://en.wikipedia.org/wiki/Deep_Web#cite_note-2) is based on disagrees:
http://www.lesk.com/mlesk/ksg97/ksg.html
That says it was 20 TB, not 3000 TB.
Or am I reading this wrong?
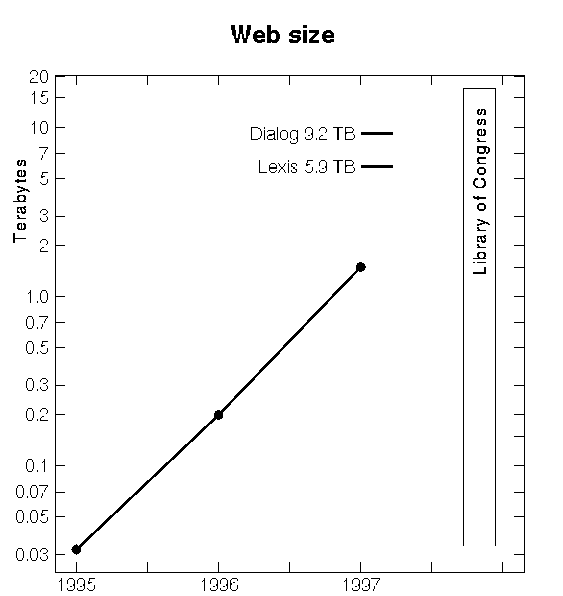
That chart didn't include all the audio and video recording files. When you add that, it gets to 3000 TB.
Yeah, that was probably about right.
If it were only 20 TB, it would be theoretically posible to mirror the entire internet in your basement with a few thousand dollars worth of hard drives.
I thought that the internet was being measured in petabytes now.
“Estimating that is a fairly difficult task, but one person made an estimate not so long ago who can probably be trusted to have a good idea. Eric Schmidt, the CEO of Google, the world’s largest index of the Internet, estimated the size at roughly 5 million terabytes of data. That’s over 5 billion gigabytes of data, or 5 trillion megabytes. Schmidt further noted that in its seven years of operations, Google has indexed roughly 200 terabytes of that, or .004% of the total size.”
http://www.wisegeek.com/how-big-is-the-internet.htm
Great list, thanks.
Here’s another that will get you going: http://www.wolframalpha.com/
It not only digs out the info, but can figure out the right answer. Go hit the link for Stephen Wolfram’s Info, it’s a 13 minute video that shows the power W|A has under the covers.
Disclaimer: Opinions posted on Free Republic are those of the individual posters and do not necessarily represent the opinion of Free Republic or its management. All materials posted herein are protected by copyright law and the exemption for fair use of copyrighted works.